





我是怎么学HLS
本人是大二开始接触FPGA,研一研二做了两个大型的FPGA项目。一年多的HLS学习开发经验,在某信号处理系统中,采用HLS设计了核心算法,并迭代优化多版,最终满足了纯HDL设计的指标要求。
我学习HLS的用途是用于实现信号处理算法,基本都是从零手搓,只会调用FFT、FIR等硬IP,对于调图像处理等软件库缺少经验分享。
下面的教程本来是写给组内师弟师妹看的,现在稍作整理,给其他准备学习HLS的同学、工程师,指下方向,尽微薄之力。
0、前言
0.1 谁适合学习HLS
需要有半年以上的verilog编写经验的人,这里的半年不包含学习时间。
HLS并不是写C/C++实现功能,需要针对代码背后的硬件实现进行优化,做到C与硬件框架的一一映射,没有半年的verilog设计经验是缺乏这种思维的。通常优化算法占用80%往上的时间,经验充足了这个时间占比会缩短。
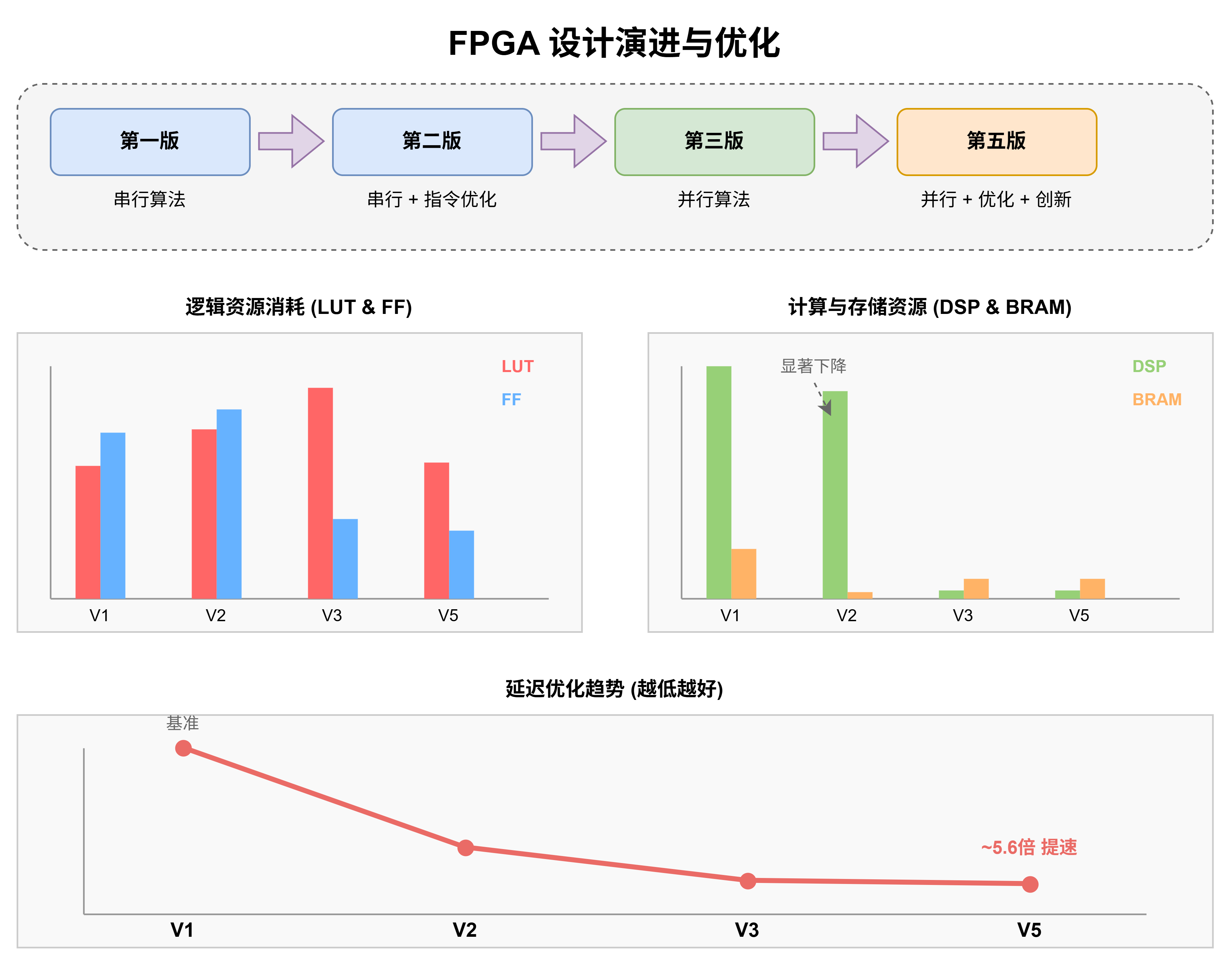
下图是我对某个算法,优化过程的大致示意图。保证整体趋势的前提下,我做了数值的变动,比例都是大致的。
0.2 vivado的版本
我的学习路线是,先用vivado2021的 vivado hls跟着UG871教程学习,后续采用vivado2024的vitis进行工程开发。
HLS是将C/C++转换成HDL语言,这个转换过程与软件背后的优化算法息息相关,而这个算法更新迭代较快,同样的代码,用2018版本的vivado hls编译出来的,与2025 版本的vitis编译出来,完全是两个结果,最新版本的比老版本快40%不止资源还更少,这都得益于算法的改变。
有很多人vivado选择老版本,比如2018.3版本,说这个版本最稳定。我对此持保留态度,至少在研究生阶段没有什么影响。
- 传统的HDL开发,vivado的版本无所谓,因为优化算法已经很完善了,新版本并不会带来多少好处。至于稳定性,我个人使用经验来看,都差不多,我们日常开发并不会碰到BUG,也许什么高级功能有BUG?
- HLS开发新的版本优化更好。
- 我们应该拥抱新技术,固守不变只会落后挨打。
1、学习路线
1.1 入门
1.1.1 UG871
一本动手实验手册。 它通过一系列精心设计的实验,手把手地教如何使用Vitis HLS工具。 内容从最基础的创建项目、C仿真、综合、C/RTL联合仿真,到应用PIPELINE、UNROLL等核心优化指令来提升设计性能、降低资源占用的全过程。
跟着他做过一遍后,会对hls有个基础的认知,但是光有这些还不够,如果想要立马实现一个复杂的hls工程,恐怕会觉得力不从心。
主要精力放在第2、4、6、7章,这四章构成了Vitis HLS开发思想的骨架。能熟练运用Analysis Perspective分析性能瓶颈,并选择合适的优化指令(PIPELINE, UNROLL, ARRAY_PARTITION, DATAFLOW等)时候,HLS算是入门了。
1.1.2 高亚军
1.1.3 Parallel Programming for FPGAs
1.1.4 其他教程
正点等的HLS教材,不要在他们上面浪费时间。
下面这个教程还可以。这一篇对于VITIS HLS的操作和编写讲解的非常详细,并且引入了许多概念和理解。缺点是没有去vivado里面仿真。
台大的课程也还不错,不过学习过上面的内容后,这个教程就显得有些鸡肋了。
1.2、深入
1.2.1 ug1399
1.2.2 调用硬件ip
HLS设计中,是可以直接调用vivado中的硬件ip的,这极大的提高了资源利用和运行效率。“深入”阶段,只需要调用出FFT和FIR库就可以,目的是学会调用方法,等项目中用到了具体某个ip,再查询“字典”学习就可以。

1.2.3 Parallel Programming for FPGAs
学习第三章之外的章节,并不一定要去跟着实现算法,重点学习教程中的设计思想,如果把算法转换成HLS代码,同时通过指令和修改C/C++写法,尽可能的利于硬件实现,优化硬件并行性。
1.3、其他
1.3.1 ai辅助
ai的发展迅速,我们不能一直守旧,用“古法编程”的方式开发程序。HLS是一个将C/C++转换成硬件描述语言的一个工具,大模型编写HDL不方便,但是编写C/C++这一样的高级语言信手拈来,因此HLS是ai大模型与FPGA硬件开发的不错切入口。
我们开发HLS项目的过程中,一定要用好ai,既不能抗拒使用它,无视时代的进步;也不能过分依赖他,目前AI大模型对硬件的理解仍然有限,对于需要深度优化的设计,仍然需要人去优化实现。实际开发过程中,实现功能其实用不了多久,优化算法会占用80%往上的时间。
如果未来AI发展的足够好了,也许AI->HLS->HDL是不错的路子,甚至直接淘汰掉HLS这一环,AI->HDL。不过当前AI的能力(claude4)是不足的。写出来能用,但也只是能用了,要是优化资源和时序问题,那么维护起来就是火葬场,经常用AI并且尝试去优化维护的同学一定深有体会。
1.3.2 创新点与毕业
能做HLS的师弟师妹(应该没有师妹)是非常幸运的,这个方向非常好出创新点,HLS是一个实现工具,用于实现算法,我们可以在算法上进行创新,并用HLS快速验证实现;也可以对于复杂、HDL不便于实现的算法,进行硬件实现,很多前人因为HDL设计复杂没有做过,你实现了,甚至是提出一种不错的HLS实现框架,这都是未来毕业论文的闪光点。
必须要提醒一点,HLS在学生秋招中,认可度不高。等你学习后会发现,这个技术如果投入生产,确实鸡肋,只能用于定制化和快速验证的场景。
笔者曾投递的论文,就是算子创新+HLS验证。
1.3.3 学习时间
UG871:约 48 - 66 小时
第一部分:HLS基础与核心优化 (建议学习重点)
这部分是掌握HLS思想和技术的基石,建议投入最主要的精力。
| 章节 | 主要内容 | 预估学习时间 | 关键学习目标与注意事项 |
|---|---|---|---|
| Ch 2: HLS Introduction | HLS设计全流程入门 | 5 - 6 小时 | 目标: 跑通第一个完整的HLS项目,建立宏观认识。 |
| Lab 1: 必须掌握!从创建项目到C仿真、综合、C/RTL联合仿真、导出IP的每一步都要亲手操作。 | |||
| Lab 2: Tcl脚本是自动化和可复现设计的关键,理解即可。 | |||
| Lab 3: 核心! 首次接触“解决方案(Solution)”和优化指令,要仔细对比不同Solution带来的性能和资源差异。 | |||
| Ch 3: C Validation | C代码验证与调试 | 3 - 4 小时 | 目标: 掌握如何编写一个好的自验证测试平台(Testbench),并学会使用HLS的C调试器。 |
| Lab 1: 重点理解一个好的Testbench为何能自动化后续的RTL验证。 | |||
Lab 2 & 3: 了解对任意精度数据类型的调试方法。注意C++的ap_int类型比C的ap_cint更易于调试。 | |||
| Ch 4: Interface Synthesis | 接口综合 | 8 - 10 小时 | 目标: 理解HLS如何将C函数参数映射为硬件端口,这是将HLS模块集成到系统中的关键。 |
Lab 1 & 2: 掌握块级协议(ap_ctrl_hs)和端口级协议(ap_vld, ap_ack)。 | |||
Lab 3: 核心! 重点学习如何将数组映射为RAM和FIFO接口,以及ARRAY_PARTITION指令如何将一个RAM接口拆分为多个,以提高并行访问能力。 | |||
| Lab 4: AXI接口是与处理器和DMA交互的标准,必须掌握。 | |||
| Ch 5: Arbitrary Precision Types | 任意精度数据类型 | 2 - 3 小时 | 目标: 理解使用ap_int和ap_fixed代替标准C类型对节省硬件资源的巨大好处。 |
关键: 对比Lab1(float)和Lab2(ap_fixed)的综合报告,直观感受资源(特别是DSP)的大幅减少。 | |||
| Ch 6: Design Analysis | 设计分析 | 6 - 8 小时 | 目标: 本手册最核心的章节之一! 学会使用Analysis Perspective来分析性能瓶颈。 |
| 方法: 这是一个连贯的长实验,请务必耐心完成每一步。学会看懂Schedule Viewer,找出导致延迟(Latency)和启动间隔(Interval)过长的原因,例如数据依赖、内存端口瓶颈等。 | |||
| Ch 7: Design Optimization | 设计优化 | 5 - 7 小时 | 目标: 本手册最核心的章节之二! 将第6章学到的分析技能应用于实际优化。 |
Lab 1: 重点理解循环依赖(Loop Dependencies)和资源瓶颈是如何限制流水线性能的,以及如何用ARRAY_RESHAPE等指令解决。对比函数流水线和循环流水线的优劣。 | |||
| Lab 2: 领悟一个重要思想:有时工具的优化是有限的,必须通过修改C代码结构来解锁更高性能。 | |||
| Ch 8: RTL Verification | RTL验证 | 3 - 4 小时 | 目标: 学会如何使用C/RTL联合仿真来验证硬件设计的正确性,并生成波形文件进行调试。 |
| Lab 1: 再次强调自验证Testbench的重要性。 | |||
| Lab 2 & 3: 掌握生成波形文件并在Vivado或第三方仿真工具中查看的方法,这是调试硬件行为的必备技能。 |
第二部分:系统级集成与应用 (建议根据需求选学)
这部分内容涉及将HLS IP集成到更复杂的系统中,需要学生具备一定的Vivado和嵌入式系统基础。
| 章节 | 主要内容 | 预估学习时间 | 关键学习目标与注意事项 |
|---|---|---|---|
| Ch 9: Using HLS IP in IP Integrator | 在Vivado IPI中集成HLS IP | 4 - 6 小时 | 前提: 需要对Vivado的IP Integrator有基本了解。 |
| 目标: 学会将HLS生成的IP核与其他的Xilinx IP(如FFT)连接起来,构建一个简单的IP子系统。 | |||
| Ch 10: Using HLS IP in a Zynq SoC Design | 在Zynq SoC中集成HLS IP | 10 - 15 小时 | 前提: 需要嵌入式系统基础,了解Zynq架构(PS+PL),并最好有实体开发板。 |
| 目标: 掌握软硬件协同设计的完整流程。 | |||
| Lab 1: 学习通过AXI-Lite接口,让CPU(软件)来控制HLS模块(硬件)。 | |||
| Lab 2: 学习通过AXI-Stream和DMA,实现CPU内存与HLS模块之间的高速数据流传输,这是性能加速的关键。 | |||
| Ch 11: Using HLS IP in System Generator | 在System Generator中集成HLS IP | 2 - 3 小时 | 前提: 需要有Matlab/Simulink和System Generator使用经验。 |
| 目标: 了解HLS IP在DSP设计流程中的应用。对于非DSP方向的学生,此章节可以选学或跳过。 |
《Parallel Programming for FPGAs》前三章:约 15 - 19 小时
| 章节 | 主要内容 (根据中文版目录) | 预估学习时间 | 关键学习目标与实践关联 |
|---|---|---|---|
| 第1章: FPGA并行计算思想 | 介绍FPGA与CPU/GPU的根本区别,引入空间计算、延迟(Latency)和吞吐率(Throughput)等核心概念。 | 3 - 4 小时 | 学习目标: 从根本上转变思维,从习惯的CPU“时间串行”思维,切换到FPGA的“空间并行”思维。 |
实践关联: 这是理解HLS所有性能报告的基础。当你在UG871的报告中看到Latency和Interval这两个指标时,本章会告诉你它们在硬件层面的真正含义。你会明白,HLS优化的核心目标,往往是牺牲一定的初始延迟(Latency),来换取极致的吞-吐率(通过降低Interval)。 | |||
| 第2章: Vitis HLS入门 | 宏观介绍HLS的设计流程,包括C代码、测试平台(Testbench)、综合、验证和IP导出。 | 4 - 5 小时 | 学习目标: 系统化地理解HLS工具的工作流程,将UG871中的零散操作串联成一个完整的理论框架。 |
| 实践关联: 如果说UG871的第2章是带你“走了一遍流程”,那么本书的第2章就是给你一张“流程地图”,并告诉你每个站点(C仿真、综合、C/RTL联仿)的意义和目的。特别是对Testbench的重要性的论述,会让你更加深刻地理解为什么一个好的测试平台是HLS项目的生命线。 | |||
| 第3章: 程序优化方法 | 本书前三章的精华所在! 详细讲解HLS最核心的几大优化技术背后的硬件原理。 | 8 - 10 小时 | 学习目标: 彻底搞懂PIPELINE, DATAFLOW, ARRAY_PARTITION等关键优化指令为什么能起作用。 |
| 实践关联: 这是你从“会用工具”到“懂工具”的飞跃。 | |||
函数和循环流水(Pipelining): 读完这部分,你会明白UG871中加入PIPELINE指令后,Schedule Viewer里那些操作是如何被重叠调度到不同时钟周期,从而实现II=1的。 | |||
任务级流水线 (Dataflow): 这会解释UG871第6章DCT案例中,为什么最后使用DATAFLOW优化,能让read_data, dct_2d, write_data这几个函数像工厂流水线一样并行工作,从而大幅降低整体Interval。 | |||
数组划分 (Array Partitioning): 这是另一个核心。你会理解为什么默认情况下数组会被综合成Block RAM,而BRAM的端口数量有限(通常是2个),这会成为并行处理的瓶-颈。ARRAY_PARTITION指令就是打破这个瓶颈,将一个BRAM拆成多个小RAM或大量寄存器,提供更多的并行访问端口。这完美解释了UG871第7章矩阵乘法中遇到的性能问题和解决方法。 |
后记
我把需要的文档材料都整理好,放在了公众号:四臂西瓜。后台回复:hls学习路线
部分信息可能已经过时